Clinical Trial Software Development Services
In healthcare IT since 2025, ScienceSoft builds and supports clinical trial software that accelerates trial speed, enhances data quality, and optimizes resource utilization through intelligent automation and analytics. Our principal architects design software that effortlessly handles diverse data formats, integrates with even the most complex legacy systems, and easily adapts to protocol amendments and shifting regulatory requirements.

Clinical trial software development services include design, development, modernization, support, and evolution of solutions for biomedical research organizations.
Essential components of clinical trial software ecosystems include a clinical trials management system (CTMS), electronic data capture (EDC) software, a clinical data management system (CDMS), statistical computing environment (SCE) software, electronic clinical outcome assessment (eCOA) software, and more.
Custom clinical trial software helps overcome the following limitations of ready-made systems:
- Inability to adapt ready-made software to complex protocol requirements or specific regulatory demands in the target countries.
- Inability to integrate all the required external data sources, for example, a specific oncology network’s HIE or oncology patient registries.
- Challenges with integrating the solution with other systems of a research organization, especially the legacy ones or those from different providers.
Why Entrust Your Clinical Trial Software Project to ScienceSoft
- Since 2005 in healthcare software development.
- 150+ successful projects in the domain.
- Since 1989 in data analytics, data science, and AI.
- Expertise in healthcare interoperability (FHIR, HL7, USCDI, CCDA), medical coding and terminology (ICD-10, CPT, LOINC, SNOMED, RxNorm), and medical imaging standards (DICOM).
- Experience in meeting GCP, FDA, HIPAA, HITECH, GDPR, and 21st Century Cures Act requirements.
- An in-house Architecture Center of Excellence to ensure the optimal balance of performance, cost, and scalability for clinical trial solutions.
Our awards and partnerships

Featured among Healthcare IT Services Leaders in the 2022 and 2024 SPARK Matrix
Named among America’s Fastest-Growing Companies by Financial Times, 4 years in a row

Recognized on Newsweek’s 2025 America’s Most Reliable Companies List

Recognized by Health Tech Newspaper awards for the third time

Top Healthcare IT Developer and Advisor by Black Book™ survey 2023

Named Best in Class in Medical Device Connectivity by Frost & Sullivan (2023)
Listed in IAOP’s 2025 Global Outsourcing 100 for the 4th year running

ISO 13485-certified quality management system

ISO 27001-certified security management system
Clinical Trial Solutions We Build, Support, and Evolve
![]()
A CTMS helps research organizations and sponsors manage all operational aspects of a clinical trial, from study planning and patient recruitment to budgeting, documentation, and site management. It also helps to monitor study progress and detect study protocol deviations.
![]()
A CDMS is used to standardize collected trial data, incorporate data from external sources, and unify medical terminology. It can also automate query management and mapping of data to the standard structured tabulation model.
![]()
Electronic data capture (EDC) systems
An EDC collects patient data during site visits and through remote tools, such as eCOA forms and wearable devices. It also captures patient data from lab results, imaging studies, and other diagnostic tests.
![]()
eConsent software
This tool enables the creation, editing, versioning, and approval of informed consent documents. It allows patients to access trial information online and facilitates the remote conduct of the informed consent process.
![]()
This software randomizes clinical trial participants and manages blinded patient treatment data. It is also used to automate investigational product (IP) shipment and dispensing and keep accountability records.
![]()
eCOA software is used to remotely collect data on the safety and efficacy of investigational treatments, either through self-report patient diaries or through data entry by clinical raters during remote or on-site patient visits.
![]()
This software consolidates site data (clinical data, operational data, and compliance indicators) to enable CRAs to perform remote monitoring visits and other remote site oversight activities. It can be used to indicate compliance gaps, conduct regular risk assessments, and support risk management activities.
![]()
An eTMF helps with creating, organizing, and managing clinical trial and site documentation. It is used to control data quality, track documentation completeness, and prepare trial data for audits and inspections.
![]()
Regulatory information management (RIM) systems
This tool enables the creation, editing, version control, approval, submission, and archiving of reports submitted to health authorities and ethical committees.
![]()
Pharmacovigilance systems
This software helps monitor, document, and report adverse event cases. It can also detect and assess safety signals and send routine safety updates to regulators.
![]()
Such software helps monitor study progress, track site performance, and identify operational bottlenecks. Analytics solutions also automate data processing and verification and offer tools for data mining, predictive modeling, and trend analysis.
![]()
With clinical trial portals, patients can explore trial details, apply for participation, and take part in trial activities from home. The portals also enable patients to access their health information and receive guidance and training on performing research activities.
![]()
Medical supply chain management portals enable research organizations to source suppliers, track shipments, and manage procurement documents, such as contracts, purchase orders, and invoices.
AI Capabilities for Clinical Trial Software and Their Typical Use Cases
ScienceSoft can enhance the automation and analytical effectiveness of clinical trial software with AI capabilities, such as natural language processing (NLP), clinical text mining, sentiment analysis, pattern recognition, anomaly detection, predictive modeling, and more.
Below, our business analysts have listed AI use cases that have proven to be the most effective in improving research data quality and reducing trial timelines and costs. Their choice is backed by feedback from our biomedical R&D clients as well as reports from IT leaders in the field. The business value metrics that we've included in the table come from the 2025 McKinsey report.
![]()
Trial design assistant
- Automatic summarization of real-world evidence and historical trial data.
- Optimizing inclusion/exclusion criteria and trial endpoints based on recruitment and research timeline forecasts.
- Automated protocol drafting and protocol quality control.
Systems: a clinical trial management system (CTMS).
Reported value: 10–20% higher cost efficiency, 5–10% trial acceleration, 30–50% fewer protocol amendments.
![]()
Trial start-up engine
- Forecasting which sites will recruit the fastest based on EHR and claim data analysis.
- AI-assisted site feasibility assessment.
- Auto-generation of localized informed consent forms and site initiation documents.
Systems: a clinical trial management system (CTMS).
Reported value: 30% faster site activation, 10–20% faster enrollment.
![]()
Investigator AI assistant
- Conversational AI for providing informational support and training on how to complete the investigator’s tasks (e.g., patient eligibility assessment).
- Scheduling assistant for automatically grouping and prioritizing tasks, resolving task conflicts, and setting intelligent reminders on planned activities.
- Drafting site documents (e.g., adverse event reports) and assisting with data entry via hints and error alerts.
- Recommendations on next-best action (e.g., following up on missed eCRF entries) based on performance trend analysis.
Systems: an investigator site portal, a clinical trial management system (CTMS), and electronic data capture (EDC) software.
Reported value: 20% higher cost efficiency, 10–20% faster enrollment.
![]()
Trial participant AI chatbot
- Answers to patient natural language queries, e.g., questions on the study details, participation-related issues.
- Intelligent reminders on upcoming study activities (e.g., taking investigational drugs, completing the diary, preparing for upcoming visits).
- Personalized messages, such as motivational messages and summarized study progress updates, to enhance patient engagement.
Systems: a trial participant portal or an app.
Reported value: 30% less patient dropout, 20% higher patient satisfaction.
![]()
Data management engine
- Automated mapping of clinical and operational data to generate research databases (regulatory, genomic, radiology databases, etc.).
- AI-based data defect detection, with automatic creation of EDC queries to fix obvious errors by site investigators or flagging potential issues for review by data managers.
- Automatic management of EDC queries, including prioritization, assignee allocation, deadline tracking, corrected data monitoring, and escalation to data managers if needed.
- An assistant for analyzing patient profile quality and tracing the sources of data inconsistencies.
Systems: a clinical data management system (CDMS).
Reported value: 30% higher cost efficiency, 70% fewer manual queries.
![]()
Site monitoring assistant
- Detection of site data defects and compliance gaps based on trend analysis.
- Automated risk indicator assessment using historical trial data and site data of the ongoing trial.
- Identifying performance patterns (e.g., slow query resolution or low enrollment rates), forecasting risks (such as delayed study milestones), and automatically suggesting corrective measures.
- Personalized suggestions on how to enhance investigator engagement.
Systems: a risk-based quality monitoring (RBQM) system, remote trial monitoring software.
Reported value: 50% fewer protocol deviations, 20% higher investigator satisfaction.
![]()
Biostatistics builder
- Automatic standard statistical analysis of research data (e.g., efficacy, safety, population pharmacokinetics indicators).
- Biostatistical database auto-generation.
- Automated quality control of biostatistical data.
Systems: statistical computing environment (SCE) software.
Reported value: 30–50% higher cost efficiency.
![]()
Pharmacovigilance engine
- Auto-drafting of adverse event reports and annual safety reports.
- Automated adverse event case collection, tracking, and reporting.
- Adverse events detection in integrated real-world patient data for post-marketing pharmacovigilance.
- AI-driven safety signal detection, assessment, and management.
Systems: a clinical data management system (CDMS), pharmacovigilance software.
Reported value: 30% higher cost efficiency.
![]()
Submission document writer
- Auto-generation of standard tables, listings, and figures (TLFs).
- Auto-drafting of a clinical study report and other submission documents.
- Automatic quality control of clinical study documents.
Systems: a regulatory information management (RIM) system, an electronic trial master file (eTMF).
Reported value: 40% faster document preparation, 59% fewer quality control issues, 50% higher cost efficiency.
Choose the Service Option That Fits Your Research Organization's Needs
![]()
Consulting on clinical trial software implementation
We define the optimal feature set to automate your specific workflows, suggest cost-effective architecture and tech stack options, and provide practical guidance on implementing security and compliance mechanisms in clinical trial software. We can provide you with a detailed project roadmap that includes accurate time and cost estimates, as well as a comprehensive risk management plan.
![]()
End-to-end clinical trial software development
We take care of the entire development process from feature gathering and architecture design to user acceptance testing and deployment. Upon release, we prepare comprehensive software documentation and provide a one-month post-launch support to fix any remaining software issues. Additionally, we can provide user training if needed.
![]()
Low-code development for clinical trial software modules
With low-code development, you can get robust functionality while keeping the solution budget-friendly. For example, we can apply low-code techs such as Power Apps to build a study setup module. You can get a simple drag-and-drop interface with templates that let users quickly configure every required workflow, from randomization and data validation to payment processing and supply logistics. It also allows for implementing mid-study changes according to protocol amendments.
![]()
Clinical trial software support, monitoring, and troubleshooting
We ensure the reliable and secure operation of clinical trial software through continuous software monitoring and system maintenance. We detect and resolve performance issues, configuration errors, and data inconsistencies while ensuring compliance with regulations such as GCP, HIPAA, GDPR, and the Cures Act. We also provide L1–L3 support to clinical trial sponsors, CROs, site staff, and other system users.
![]()
Clinical trial software modernization
For clinical trial software that’s already in use in your organization, we can address legacy issues such as inefficient workflows and user workspaces, data silos, security vulnerabilities, and compliance gaps. We can also adjust the software to meet new regulatory requirements, integrate it with new systems, external services, and data sources, and add new features, including AI modules.
Want to see how we can help you speed up research cycles?
Book a consultation, and ScienceSoft’s experts with extensive experience in clinical trial software will reach out to you.
Sample Architecture for a Clinical Trial Software Ecosystem
This example architecture of a clinical trial software ecosystem, designed by our principal solution architects on Amazon Web Services (AWS) technologies, is modular, cloud-native, microservices-driven, and follows a compliance-first approach. It ensures quick integration with a wide range of data sources, supports full automation of trial activities, and offers workflow adaptability to protocol amendments.
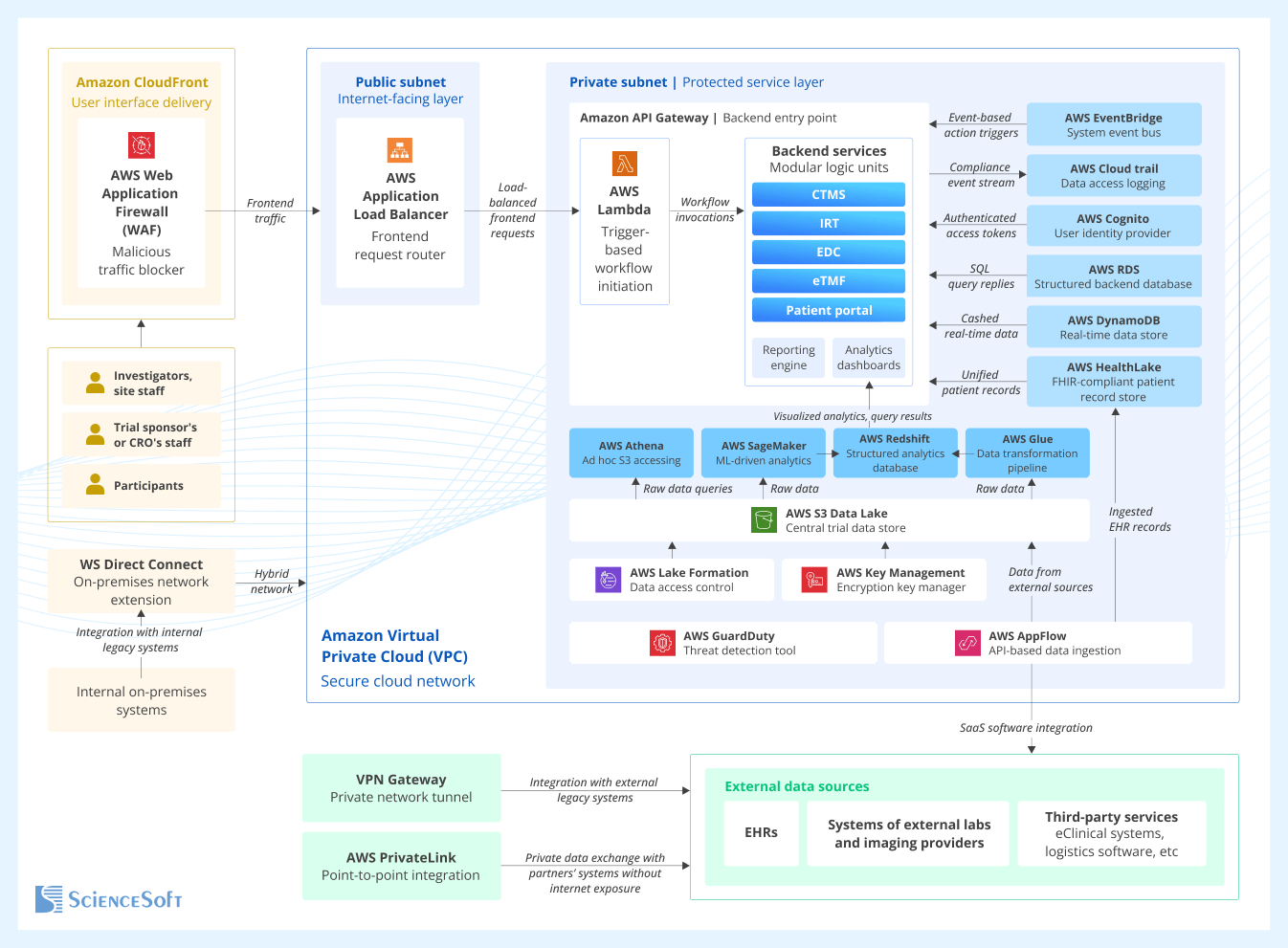
User access and trial workflow orchestration
Investigators, site staff, a trial sponsor’s or CRO’s staff, and patients access clinical trial software systems via secure web dashboards or mobile apps. Through these interfaces, they can view trial data, perform role-specific tasks, and submit both structured (forms, metadata) and unstructured data (scanned documents, medical images, PDFs, etc.).
All frontend traffic enters the clinical trial systems through Amazon CloudFront. It accelerates the delivery of user interface assets by caching them at geographically distributed edge locations and also routes API requests to backend services, which helps reduce latency. Then the traffic is routed by the Application Load Balancer (ALB) to backend services. By applying intelligent routing logic, the ALB ensures high availability and elastic scaling during periods of high load, such as site activation waves or last-patient-out (LPO) data processing.
From the load balancer, frontend API requests are routed to Amazon API Gateway, which acts as the controlled entry point into the backend. The gateway checks if the requests are properly structured, enforces request rate limits for each client to prevent overuse, and directs calls to the correct backend services.
Business logic execution is handled by AWS Lambda functions deployed in the private subnet. Each function performs an isolated step in the trial workflow and is triggered either by incoming API requests or event notifications from other system components.
Amazon EventBridge serves as a unified event bus for triggering backend automation. It receives structured events from both internal services (e.g., new patient enrollment) and external platforms (e.g., new lab results) and forwards them to Lambda for processing. This triggers the execution of atomic workflow steps. For example, submitting a site setup form can trigger a sequence that registers the new site in the CTMS, archives site documentation, and schedules the required site monitoring visits.
Through the use of event-driven triggers, isolated atomic backend tasks, and real-time data flows, highly efficient automation becomes possible, which accelerates effort-intensive trial tasks like data reconciliation or site monitoring.
Core trial operations
Core system backend includes modular services, each executing an isolated trial automation step in response to specific triggers. Together, they cover the core functionality of all components in the clinical trial software ecosystem, such as a CTMS, an IRT, an EDC, an eTMF, etc.
Each service is deployed and runs in isolation, without sharing infrastructure or state, which means trial designers can easily modify data processing rules, add logic tailored to specific countries, or create new forms without affecting unrelated components. This ensures short setup times and streamlined mid-trial changes in line with protocol amendments.
Services exchange data with other components via API calls or event messages. They use DynamoDB as a low-latency operational store. For example, when IRT assigns patients to trial arms, it immediately writes the group assignment results to DynamoDB so that downstream services have real-time access to allocation data. Some backend services store structured records in Amazon RDS when fast and frequent SQL queries are required. For instance, this might be used for document search in an eTMF or task tracking in a CTMS.
To support downstream analytics, audit traceability, and regulatory reporting, backend services forward all key clinical and operational data (e.g., regarding trial state, subject progress, site performance, document readiness) to the central trial data lake (Amazon S3).
Data ingestion from internal and external sources
The platform supports ingestion of operational and clinical data from diverse sources, such as central lab systems, commercial SaaS tools (e.g., eConsent or logistics software), partner CRO platforms, and EHRs. This includes data sources that rely on legacy and on-premises databases.
To achieve this, the following ingestion paths are used:
- AWS Direct Connect is used to integrate internal on-premises legacy systems. It establishes a dedicated private path into the AWS-hosted ecosystem, forming a hybrid network that covers both cloud-native and on-premises infrastructure. This enables the secure transfer of large data volumes from internal systems that require consistent throughput and cannot use the public internet due to compliance reasons.
- Amazon AppFlow ingests structured and semi-structured data (e.g., HL7 messages, FHIR resources, or other JSON-based payloads) from modern EHRs and SaaS platforms (e.g., lab software) via built-in cloud connectors. Then it applies transformation rules before forwarding this data to downstream services or the data lake.
- VPN Gateway creates an encrypted tunnel to connect with legacy hospital servers or on-site databases running in private local networks without public internet access. This connection enables secure import of exported files, scanned documents, and structured historical patient data from systems that can’t be integrated via API or cloud connectors.
- AWS PrivateLink allows secure point-to-point integration with trusted vendor systems (those hosted within AWS, with certified PrivateLink endpoints, or approved by the study sponsor). In this case, data is exchanged over private AWS channels rather than the public internet, which ensures secure transfer of sensitive trial information.
Ingested structured or unstructured data may be forwarded to Amazon S3 (the central trial data lake) for long-term storage and later processing, or routed directly to backend services, as when updates about investigational drug delivery are sent straight to the IRT.
Patient records ingested from EHR platforms in HL7 messages or FHIR resources are sent to AWS HealthLake. It restructures the data (such as diagnoses, vitals, and prescriptions) into a semantically indexed model to optimize it for querying by downstream services, custom search, and AI analytics.
Beyond accommodating both modern SaaS tools and legacy systems, this architecture enables researchers to integrate new data sources without redesigning and to connect region-specific infrastructure or new vendor platforms when needed.
Data processing and analytics
All incoming and processed data is sent to a centralized Amazon S3-based Data Lake. Raw data lands in a staging zone and then moves through AWS Glue pipelines for cleaning, transformation, and normalization. Processed outputs are loaded into Amazon Redshift, a scalable analytics store optimized for structured querying. For example, it enables automated generation of trial KPIs, such as enrollment rates and site risk scores.
Amazon SageMaker trains and applies machine learning (ML) models using data from Redshift and the data lake. For example, it can predict how quickly potential sites will recruit patients to support feasibility assessment. The outputs can be written back to Redshift or routed to operational systems such as CTMS for further action (for example, to initiate the site activation process).
Clinical teams, operations leads, and QA staff gain access to all aggregated trial metrics and ML model outputs through the analytics dashboards, which offer detailed reports and custom search capabilities. Users can also get direct SQL-based access to raw S3 files using Amazon Athena. For example, thanks to Athena’s serverless querying, auditors can instantly extract the original protocol deviation logs without the need to preload or preprocess the data.
Compliance and security
All operational and clinical data flows are tracked and controlled by a dedicated compliance layer, which is aligned with the major regulatory standards in clinical research.
Amazon CloudFront ensures all user traffic enters through encrypted TLS connections and provides built-in DDoS protection. It integrates with AWS Web Application Firewall (WAF) to block malicious payloads, unauthorized access attempts, and IPs violating regional policies. Together, they form a perimeter layer that satisfies HIPAA and 21 CFR Part 11 requirements for controlled, filtered system access.
All backend services operate inside a logically isolated Virtual Private Cloud (VPC). The API layer and other internet-facing endpoints are deployed in the public subnet. As for the sensitive compute and data services (e.g., Lambda, backend logic), they reside in the private subnet, which has no direct internet access. This segmentation ensures that only explicitly exposed interfaces are reachable externally, as required by GCP guidelines.
Amazon Cognito manages user authentication for trial participants, site investigators, and sponsor or CRO staff. It supports multi-factor authentication (MFA) and federated login, and generates time-bound tokens to enforce secure session control.
Secure ingestion of external data is achieved using AWS PrivateLink and VPN Gateway. PrivateLink enables connection with certified third-party tools without traversing the public internet. VPN Gateway establishes encrypted IPsec tunnels to isolated hospital infrastructure or legacy archives.
All data in transit is encrypted using TLS, and all data at rest (in Amazon S3, Amazon Redshift, Amazon RDS, and DynamoDB) is protected with AWS Key Management Service (KMS). The system uses either AWS-managed keys or customer-managed KMS keys with audit tracking and access revocation.
Access to data stored in S3 is governed by AWS Lake Formation, which applies fine-grained access controls. Only authorized services and IAM identities can read or write specific datasets. Redshift and Athena queries are also subject to row- and column-level permissions, ensuring patient-level data isolation across trials or sponsor roles.
Audit trails are automatically collected for all API calls, data access attempts, and configuration changes using AWS CloudTrail. These logs ensure traceability of actions such as dataset export, user access, or protocol updates, and can be provided for inspection during audits.
Amazon GuardDuty monitors network activity and service behavior for signs of potential security threats, like compromised credentials or unauthorized access attempts. It receives triggers from EventBridge and logs from system components, enabling it to detect threats in real-time and provide timely alerts to administrators.
Together, these controls ensure trial data integrity, full auditability, and regulatory readiness.
How We Handle Common Issues in Clinical Trial Software Projects
Below, ScienceSoft’s experts outline the most common technical and business challenges that arise in clinical trial software projects and explain how we address them.
![]()
Challenge #1. Integration of many diverse data sources
Research organizations typically don’t solely rely on internal systems for collecting clinical data. They also need to incorporate data from multiple external data sources, such as specialty labs, EHRs, or biobank databases. Integrating vast amounts of heterogeneous data presents a significant technical challenge. If unresolved, researchers may face a decline in data quality and have to resort to labor-intensive and prolonged data validation and analysis workflows.
Solution
![]()
Challenge #2. Difficult and lengthy setup of automated research workflows
Screening and randomization schemes, as well as the collected data sets and the rules for processing them, may differ significantly between studies. Moreover, they often change mid-study as a result of protocol amendments. If the software doesn’t offer convenient tools for configuring the study’s automated workflows, this leads to delays in study startup and protocol amendment implementation, which ultimately result in trial timeline disruptions.
Solution
![]()
Challenge #3. A fragmented ecosystem of numerous standalone solutions
Due to difficulties in integrating solutions built by different vendors, research organizations often rely on multiple standalone solutions, each covering a specific part of their research procedures. In such a fragmented ecosystem, some automated workflows get duplicated across systems, while others remain manual. This creates additional work for researchers, complicates data quality control, and slows down the research process.
Solution
What Our Healthcare Clients Say

This project is part of our ongoing research focused on addressing a critical, widespread condition impacting millions of people globally. The nature of the work required not only technical expertise but also a deep understanding of the scientific context and close cooperation between technology and healthcare professionals. The resulting Proof of Concept exceeded expectations, and we sincerely appreciated the way it was delivered. We found ScienceSoft to be dependable and forward-thinking, and we would confidently recommend them for high-responsibility projects.

bioAffinity Technologies hired ScienceSoft to help in the development of its automated data analysis software for detection of lung cancer using flow cytometry. Our project required a large amount of industry-specific methodology and algorithms to be implemented into our new software connected to EHR/LIS systems, which the team handled well. They are reliable, thorough, smart, available, extremely good communicators and very friendly.

During our cooperation, ScienceSoft proved to have vast expertise in Healthcare and Life Science industries related to the development a desktop software connected to laboratory equipment, mobile application and data analytics platform. They bang top quality talents and deep knowledge of IT technologies and approaches in accordance with ISO13485 and IEC62304 standards.

